
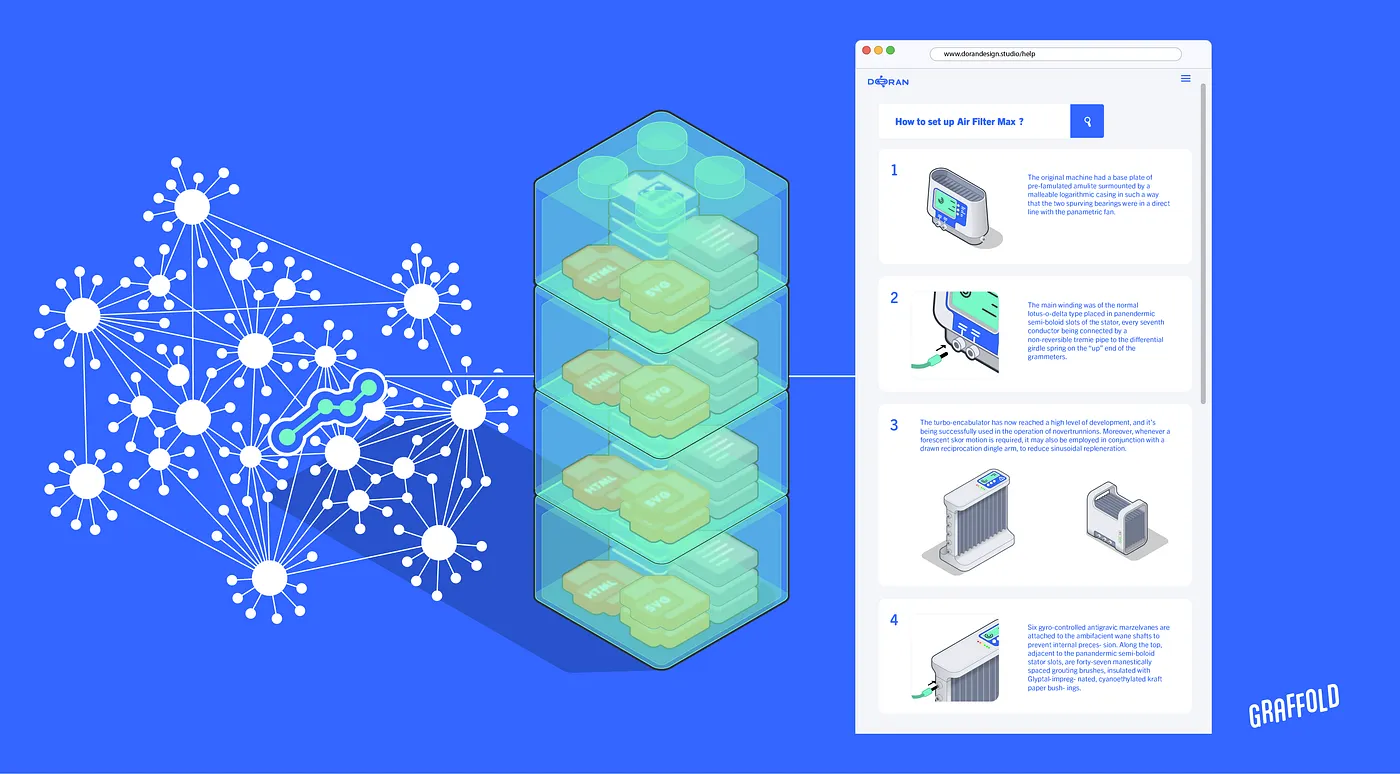
AI and knowledge graphs will transform product documentation, especially for complex, networked systems that require configuration, integration, or automation. This proposal focuses on the need to build a navigable web of linked content for those products.
People used to plan road journeys using a road atlas. These were awkward, oversized documents that didn’t fit comfortably in a car and had to be laid out on a large table so that a route could be drawn on in pencil.
There are limitations to forcing something as nonlinear as geography into a linear printed format, the pencil line would often hit the bottom edge of one page, then jump ahead several pages to continue at the top of another. Or even jump out of one atlas and into another. Then gps, map data and pathfinding algorithms were combined to serve users step-by-step instructions for almost any route, on demand.
Print format user guides have not yet been replaced by their GPS-style successor. That transition is only just beginning. We’ve been complacent, but AI is now forcing our hand. There is a major opportunity to apply new tools to the long-neglected problem of product documentation.
Users want step-by-step instructions for the specific task at hand. And just like a car journey, that task might be a completely novel route. Large Language Models (LLMs) promise they can already deliver this, and many product users believe them. ChatGPT will confidently generate step-by-step instructions for anything. The problem is, there is often no connection to an underlying map. It is making it up as it goes. We need to build the map. What follows is a proposal for how to do that.
A long time ago, products came with thick printed user guides. If the product came in a big enough box, it might look and feel like a textbook. A smaller product might have the same content squished down to novella size. These artifacts were often the butt of jokes. Something usually had to go wrong, or the user had to get truly stuck, before they were desperate enough to delve into one of these byzantine documents. But Google, YouTube, Reddit, or ChatGPT didn’t exist, so they had no choice.
Over the past 25 years, most companies have replaced their printed guides with an online PDF library and now only print a shortened Quick Start Guide. Some companies have transitioned to a content management system (CMS) or component content management system (CCMS) for documentation, if that’s you, you can skip down to Graph-Based Order, but many have not.

The online PDF saved a lot of money in print costs, with the added benefit of being available on demand. Users no longer needed to keep filing cabinets full of documentation. I still have some printed user guides in a filing cabinet, but if I really needed that information, I’d probably still Google it. You might be the same. Many of your customers definitely are.
And if I Google it, Google is less and less likely to serve me the full PDF. It prefers a help article, a Reddit thread, a YouTube video, or more recently, its own Featured Snippet or AI response. Google has discovered that people click on that stuff, they only click on a link to PDF if they absolutely have to.
Worryingly for us product people, users are increasingly going straight to AI for product questions. But have the LLMs actually read the manuals and weighted the content so that it influences the output? Often, the answer is no. Worse, it doesn’t know that it hasn’t. And worse still, the knowledge gap is completely concealed from users by the model’s default bravado.
Most product content isn’t relevant to most users. As product teams, we ship products with a set of instructions, but users interact with them in unpredictable ways. They encounter issues and use cases that weren’t anticipated. We can try to cover every possibility in the manual, but if the content is locked in a large, static PDF, it becomes overwhelming, more textbook than tool. These PDFs typically focus on a single product, while real-world usage usually involves several working together and the landscape of products it lives in is constantly changing. Not everything can be a Lego set or IKEA flatpack.
Lego is a very linear and unambiguous product. Either the user messes around with blocks and never ends up with the Millennium Falcon on the box, or they follow every step in the glossy booklet and they do. There are no conditionals, no if-this-then-that logic. The same is generally true of IKEA furniture. That’s why they can have simple, linear user manuals that people actually read.
The goal for instructional content is to be more like Lego. Lego proves that people will pay money to follow instructions (as does ChatGPT, but we’ll get to that later). Users need to get from A-B and they trust that the step-by-step content is the fastest route, so they follow it.
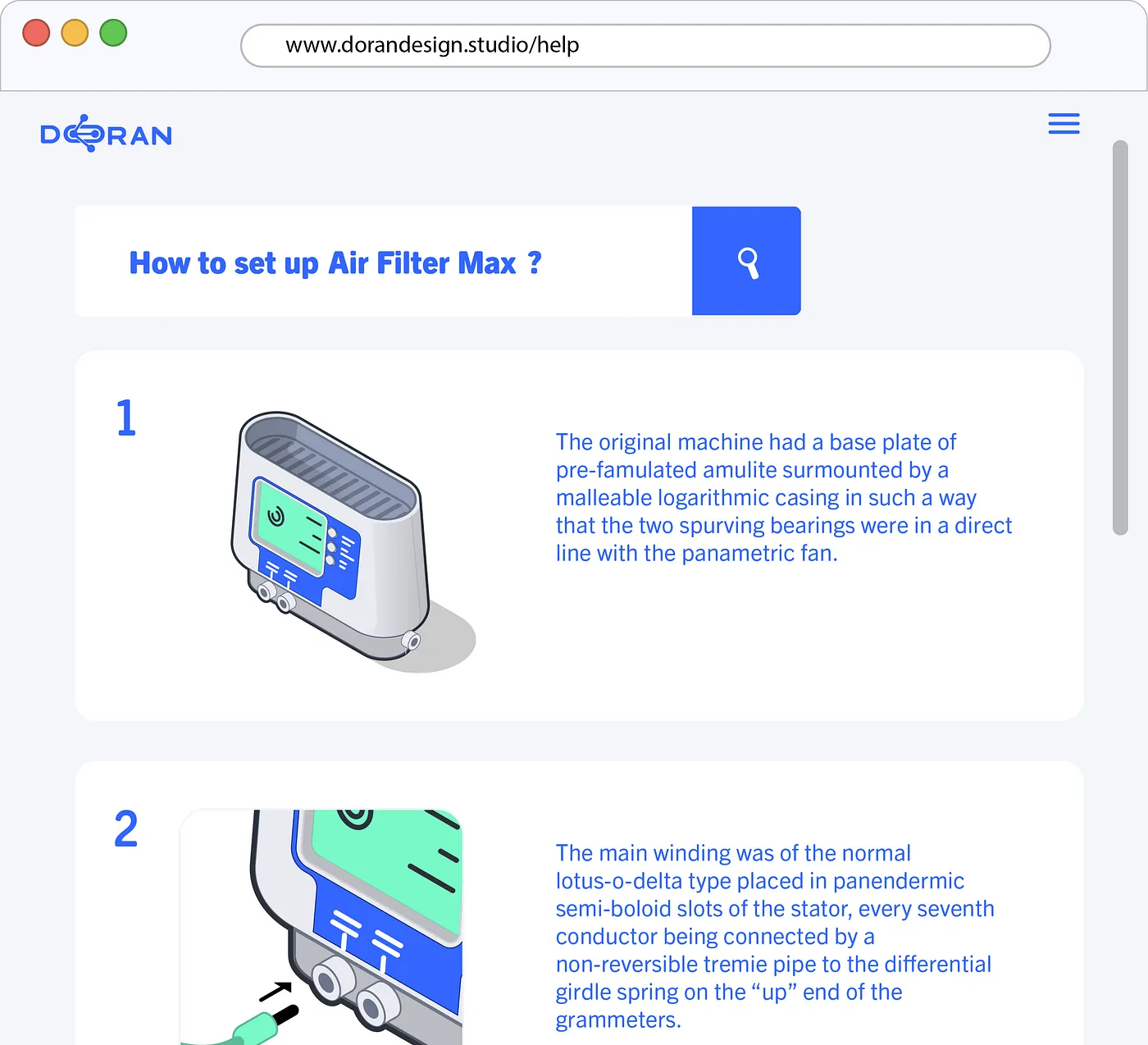
The product systems I’m talking about are more like individual Lego bricks than a full set. The full set is a configuration of multiple products, each with its own documentation. Users must first identify the pieces they need, then figure out how they fit together, either informally in their head or formally in something like an order of works document.
The printed document, or its digital PDF simulacrum, is a bad container. And it is preventing us from serving users the Lego/GPT/ Google Maps-style step-by-step instructions they obviously prefer, tailored to their specific system or problem.
The multi-PDF journey is also not the fastest route from A-B. It is like relying on multiple road atlases. The user might only need a single vector buried in a few pages, but they have to search through the whole thing. Google Maps contains all the road data and just serves the route, step by step, and people use it. People do not use road atlases anymore. And if Google Maps were just the scanned pages of a road atlas uploaded as PDFs, no one would use that either. It is time to move on from the PDF. It’s too static, too linear.
We can’t predict every configuration or use case. What’s missing is a dynamic system that can assemble those instructions on demand, based on the specific components in play and the task at hand. Users want a clear route from A to B. Lego gets to predefine the route, the final model, before the product launches. We do not have that luxury. We need something dynamic.
LLMs, which will enthusiastically prepare step-by-step instructions for any task. But as we are about to find out, unless the manufacturer’s docs are the easily digestible low-fiber variety, the model might be making it up as it goes along without ever having seen the source material. And how is the user supposed to know? That is the problem, solution and opportunity that AI offers.
To generate routes dynamically, like Google Maps, we need a system that slices the existing PDFs into manageable chunks. This requires computer vision and an LLM to parse content, a CCMS to store the output, and a knowledge graph to connect and organize everything.
PDF user guides are like celery when it comes to training large language models, mostly fiber. They can require a lot of processing for minimal value. The text, which is the useful stuff, is only a small part of the overall code and this might not even be in the same logical order as it appears on the page. The rest is just fiber; a jumbled mess of rendering instructions, embedded vector graphics and base64-encoded images.
If your product is something fairly niche, the model might not attach much weight to it or choose not to bother ingesting it at all. Humans don’t eat grass. Cows do, but they need to chew all day and have six stomachs to get anything out of it.
The first step is to build a system with the extra stomachs needed to digest and break down the existing PDF library into content that works for both people and machines. This means structured, componentized help articles with metadata and context. Content that a language model can process, Google can serve, and users can query.
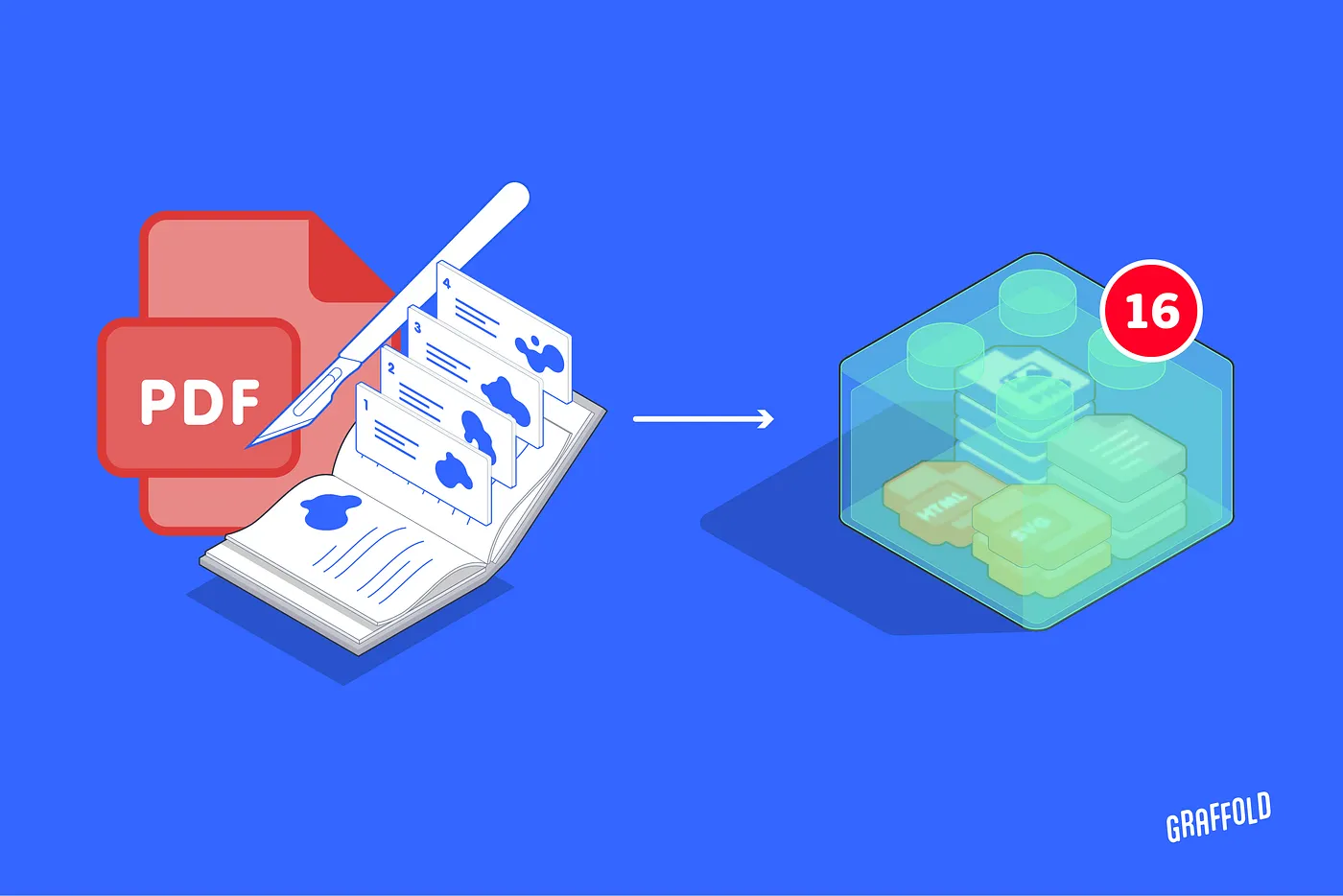
Doran Design Studio has developed such a system. The output is clean, structured material ready for a CMS or CMMS, content that Google and LLMs can easily index and train on.

All that content has been freed from its PDF containers and now needs organizing, for this we need a knowledge graph. The knowledge graph acts as the high-level map, tracking what content exists and how it all fits together with the underlying product system.
A knowledge graph is a data model that organizes real-world entities such as products, features, documents, or users, and the relationships between them. These nodes and relationships are stored in a graph database, creating a connected framework that maps your product system and the content describing it. For example:

The knowledge graph is the map, and because it’s graph-based, it closely mirrors how Google Maps handles pathfinding. Graph theory was developed for exactly this kind of challenge.
This system lets us navigate product data the way Google Maps navigates roads. The pencil line on a road atlas traced a clear route through printed geography, helping users ignore irrelevant data, just as sticky notes and highlights did in printed manuals. Once product data is digitized and structured in a graph, tools like retrieval-augmented generation (RAG) and pathfinding algorithms can traverse it. The result is step-by-step instructions, generated on demand, for any valid route.
Instead of leaving information buried in static PDFs, the knowledge graph turns it into structured, connected, and searchable data. This enables dynamic, tailored, step-by-step instructions for any task, system, or user. Content once scattered across multiple documents can now be linked and sequenced. LLMs assist not by guessing, but by retrieving the most relevant pieces and assembling them based on product logic and structured content rules, such as those borrowed from DITA.
The content can be videos, diagrams, or text, whatever fits best. Text can be cleaned up by an LLM to unify style across sources or delivered as-is. Crucially, the LLM isn’t making it up; it’s retrieving and assembling existing content.
This isn’t about rewriting manuals. It’s about replacing them with a living system that delivers precise, on-demand instructions tailored to any user or configuration. It aligns with how people now search, learn, and solve problems. This shift is already underway. Our task is to transform existing data and establish better conventions
The adoption of AI tools like ChatGPT shows that people are ready to take instructions from AI. But for those instructions to be accurate, the system needs access to high-quality data. If we want more control over the answers, we need to replace static PDF libraries with something better. That something is graph-based, and it represents a major opportunity.